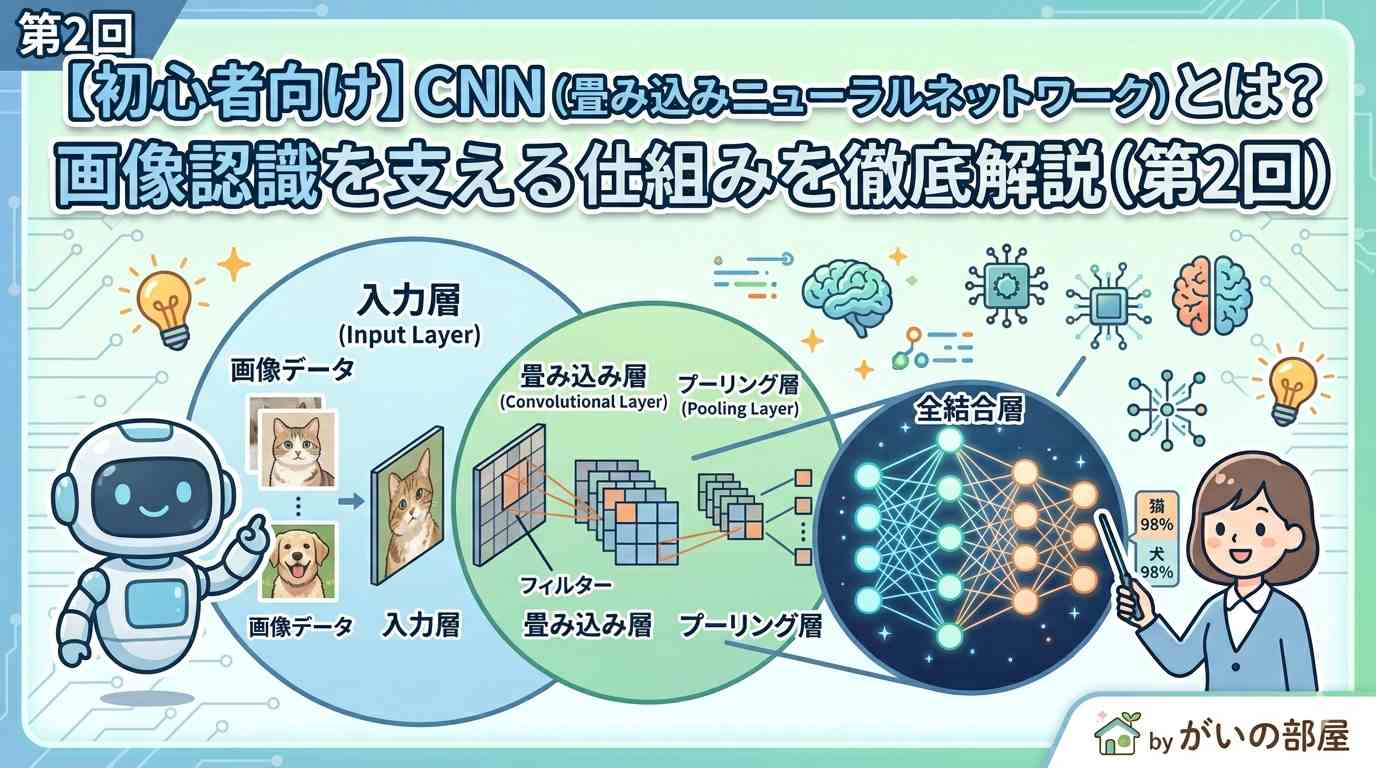
前回はディープラーニングの全体像を説明しました。今回はその中でもとくに画像認識で大活躍している CNN(Convolutional Neural Network)を詳しく見ていきましょう。
1. なぜCNNが必要だったのか?
普通のニューラルネット(全結合)の問題点
100×100ピクセルのカラー画像を扱うと…
入力ニューロン数 = 100 × 100 × 3(RGB) = 30,000個 次の層が1,000個なら → 重みは 30,000 × 1,000 = 3,000万個!
- パラメータが爆発的に増える
- 「猫が画像の左にいるか右にいるか」で別物として扱われる
- 画像の空間的な構造(隣のピクセルとの関係)を無視してしまう
CNNはこれらを 「畳み込み」 という仕組みで解決します。
2. CNNの3つの核となる仕組み
① 畳み込み層(Convolution Layer)
小さなフィルタ(カーネル)を画像にスライドさせて特徴を抽出します。学習が進むと、あるフィルタは「縦のエッジ」に反応し、別のフィルタは「横のエッジ」に反応…と、それぞれ異なる特徴を検出するようになります。
- フィルタは画像全体で 共有 される→パラメータが激減
- 位置がずれても同じ特徴を検出できる(並進不変性)
② 活性化関数(ReLU)
畳み込みの結果に 非線形性 を加えます。
ReLU(x) = max(0, x) ← マイナスは0、プラスはそのまま
シンプルですが、これがないと層を重ねても線形変換のままで意味がなくなります。
③ プーリング層(Pooling Layer)
特徴マップを縮小して、重要な情報だけ残します(例:2×2ブロックの最大値を取る Max Pooling)。
- データ量を減らして計算を高速化
- 多少の位置ずれに強くなる
- 過学習を抑える
3. CNN全体の構造
入力画像 ↓ Conv → ReLU → Conv → ReLU → Pooling (低レベル特徴) ↓ Conv → ReLU → Conv → ReLU → Pooling (中レベル特徴) ↓ Conv → ReLU → Pooling (高レベル特徴) ↓ 全結合層 → Softmax ↓ [猫: 0.92, 犬: 0.05, 鳥: 0.03]
特徴抽出パート(畳み込み+プーリング)と分類パート(全結合)の2段構えがポイントです。
4. 重要な用語
| 用語 | 意味 |
|---|---|
| カーネル / フィルタ | 畳み込みで使う小さな行列(3×3や 5×5 など) |
| ストライド | フィルタをずらす歩幅 |
| パディング | 入力の周りを0で埋めてサイズ縮小を防ぐ |
| 特徴マップ | 畳み込みの出力。フィルタの数だけできる |
| チャンネル | RGBの3、または特徴マップの枚数 |
5. 歴史的な代表モデル
| モデル | 年 | 特徴 |
|---|---|---|
| LeNet-5 | 1998 | 元祖CNN。手書き数字認識 |
| AlexNet | 2012 | ImageNet優勝、ディープラーニングブームの火付け役 |
| VGG | 2014 | 3×3フィルタを重ねるシンプルな構造 |
| GoogLeNet (Inception) | 2014 | 複数サイズのフィルタを並列に使う |
| ResNet | 2015 | 「残差接続」で100層超えを可能に。今も基盤 |
| EfficientNet | 2019 | 精度と計算量のバランスを最適化 |
6. CNNが活躍する分野
- 画像分類:何が写っているか判定
- 物体検出:YOLO、Faster R-CNN(位置も特定)
- セグメンテーション:U-Net(ピクセル単位で分類、医療画像で活躍)
- 顔認識:FaceNet
- 画像生成:GANのベースとしても使用
7. CNNの限界と今後
近年は Vision Transformer (ViT) が画像認識でもCNNに匹敵・凌駕する成果を出しています。ただし、データが少ないときや計算リソースが限られるエッジデバイスなど、CNNは依然として強力な選択肢です。
まとめ
CNNは 「畳み込み」で画像の特徴を抽出し、「プーリング」で要点を残し、シンプルな特徴から複雑な特徴を組み上げていく 仕組みです。
とはいえ、ここまで読んで「隠れ層」と「畳み込み」が何となく難しい…と感じた方も多いはず。次回はこれらを もっとやさしいたとえ話 で解説します!
コメント