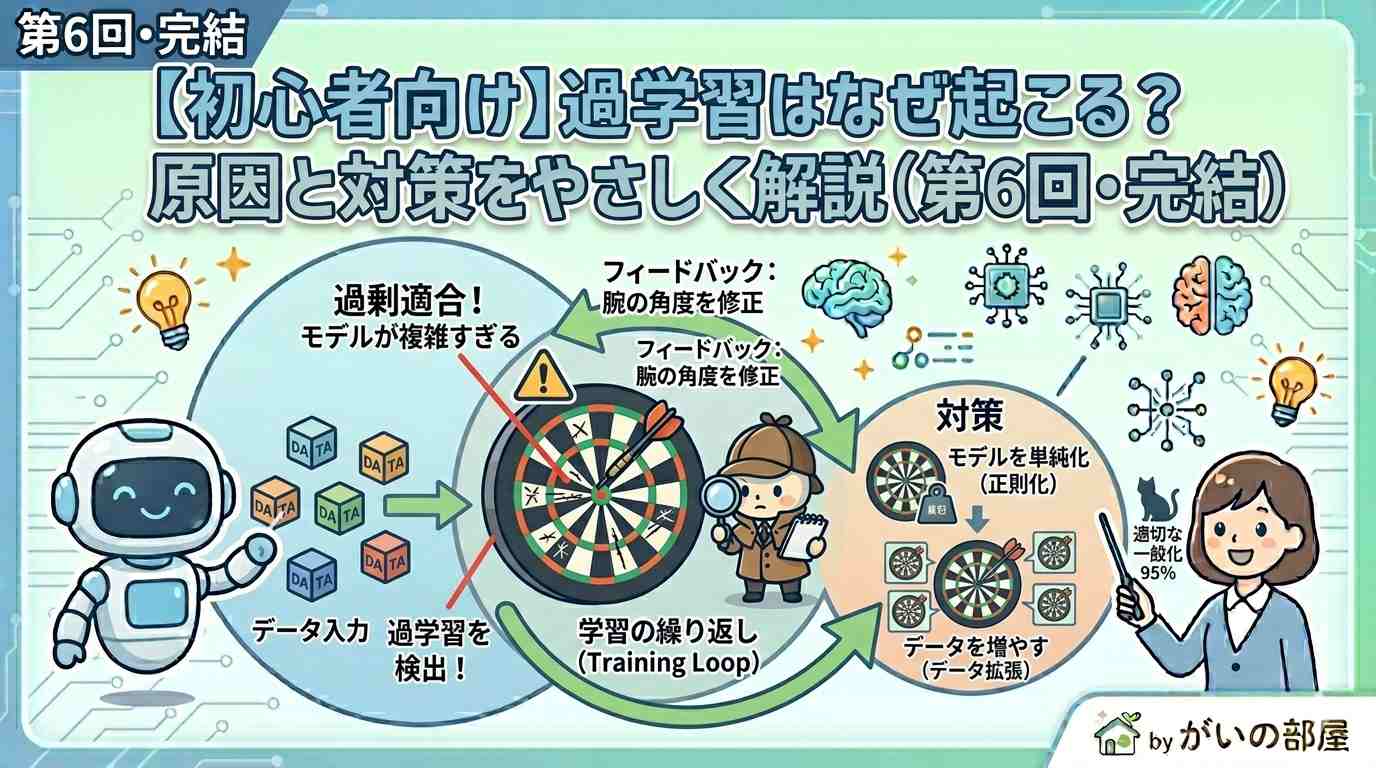
「学習しすぎると逆にダメになる」——直感に反するこの現象が 過学習(オーバーフィッティング)です。シリーズ最終回として、身近なたとえで一気に理解していきましょう。
1. 過学習って何?
ざっくり言うと 「練習問題は完璧に解けるのに、本番のテストでは点が取れない」状態です。英語で overfitting(合わせすぎ)と言うとおり、訓練データに「合わせすぎて」しまう現象です。
2. 受験生のたとえで理解する
❌ Aさん:勉強不足(未学習 / underfitting)
過去問: 10点 / 100点 本番 : 15点 / 100点
そもそも基礎ができていないパターン。
⭕ Bさん:理解して勉強(ちょうどいい学習)
過去問: 85点 / 100点 本番 : 80点 / 100点
問題の本質的なパターンを理解しているので、初見の問題にも対応できる。
⚠️ Cさん:過去問を丸暗記(過学習 / overfitting)
過去問: 100点 / 100点 ← 完璧! 本番 : 40点 / 100点 ← え!?
過去問の答えを丸暗記しただけで、少し問題文が変わると手も足も出ない状態。これがAIで起こる過学習です。
3. AIで何が起こっているのか
訓練データ(練習問題) : 99% 正解! テストデータ(本番) : 50%しか正解できない
AIが「問題のパターン」ではなく「データの細かい特徴やノイズまで」を覚えてしまうからです。
例:猫を判定するAI
- 理想の学習:耳が三角、ヒゲがある、目が縦長…という本質的な特徴を学ぶ
- 過学習したAI:「左上の3番目のピクセルが茶色」「右下にぼやけがある」など、たまたま訓練データにあっただけの特徴を覚えてしまう
4. 学習中に起こること(グラフで見る)
正解率
↑
100% │ ──────── 訓練データ(練習問題)
│ /
│ /
80% │ / ___
│ / / \__ テストデータ(本番)
│/ / \_
60% │ /
│ /
└────────────────→ 学習回数
↑ ↑
ちょうどいい ここから過学習が始まる
タイミング
- 訓練データの正解率はずっと上がり続ける
- でもテストデータの正解率は途中から下がり始める
- この「下がり始める瞬間」を超えると過学習
5. なぜ過学習が起こるのか(5つの原因)
- 原因① データが少なすぎる:猫の画像が10枚だけだと、その10枚の特徴だけを覚えてしまう
- 原因② モデルが複雑すぎる:簡単な問題に超高性能AIを使うと、記憶ゲームになる
- 原因③ 学習しすぎ:同じ問題を1万回繰り返して丸暗記
- 原因④ データの偏り:訓練画像が全部「白い猫」だと、黒猫を「猫じゃない」と判定
- 原因⑤ ノイズまで学習:間違ったラベルを含むデータをそのまま覚えてしまう
6. 過学習を防ぐ主な対策
対策① データを増やす(最強)
100枚 → 10,000枚に増やせば、多様なパターンを学べて「本質」をつかめるようになります。
対策② データ拡張(Data Augmentation)
データが少なくても、人工的に増やすテクニック。
元画像(猫1枚) ↓ ・左右反転 → 1枚 ・少し回転 → 1枚 ・色味を変える → 1枚 ・一部を隠す → 1枚 ・拡大縮小 → 1枚 ↓ 1枚 → 6枚に増えた!
対策③ Dropout(ドロップアウト)
学習中、わざとニューロンの一部を無効化します。チームで仕事するとき、毎回ランダムに休む人がいると「全員が幅広いスキルを持つ」ようになるのと同じ効果です。
対策④ 正則化(Regularization)
「数字を大きくしすぎたらペナルティ」というルールを追加し、極端な数字を避けてシンプルな解に誘導します。
対策⑤ 早期終了(Early Stopping)
テストデータの正解率が下がり始めたら、そこで学習をストップするシンプルな手法です。
対策⑥ モデルをシンプルにする
データ量に見合ったサイズにし、不必要に複雑なモデルを避けるだけでも効果があります。
7. 訓練・検証・テストデータ
過学習を見つけるために、データを 3つに分けます。
| データ | 割合の目安 | 役割 | たとえ |
|---|---|---|---|
| 訓練データ | 70% | AIに学ばせる | 教科書・問題集 |
| 検証データ | 15% | 学習中のチェック用 | 模擬試験 |
| テストデータ | 15% | 最後に1回だけ評価 | 本番試験 |
テストデータは学習中に絶対見せちゃダメ。見せたら「過去問を本番に出す不正」になってしまいます。
8. 過学習チェックリスト
- 訓練データの正解率がほぼ100%
- テストデータの正解率が大幅に低い(差が10%以上)
- 学習を続けても検証データの正解率が下がっていく
- 訓練データにない画像で誤判定が多い
1つでも当てはまったら、過学習を疑いましょう。
9. 身近な例で過学習を実感
- 受験勉強:過去5年分を丸暗記するより、基礎概念を理解して多様な問題を解くほうが応用が効く
- 料理:1冊のレシピ本をコピーするより、基本技術を学んだほうが冷蔵庫の中身で何でも作れる
- スポーツ:同じコーチの同じ練習だけより、多様な相手との試合を重ねたほうが実戦で強い
まとめ
- 過学習:訓練データに合わせすぎて、新しいデータに対応できなくなる現象
- 原因:データ不足・モデル複雑すぎ・学習しすぎ・データの偏り
- 対策:データを増やす・データ拡張・Dropout・正則化・早期終了・シンプルなモデル
一番大事なこと:「丸暗記」ではなく「理解」を目指す。AIも人間も、本質を捉えた学び方が大切なのです。
シリーズを終えて
全6回にわたったディープラーニング入門、お疲れさまでした!
- ディープラーニングとは何か(全体像)
- CNNの仕組み(画像認識)
- 隠れ層と畳み込みをたとえで理解
- フィルタの中身は「数字の表」
- AIの学習の仕組み
- 過学習の原因と対策(今回)
ここまで読んだあなたは、ディープラーニングの「ざっくりイメージ」がシッカリ身についています。これがあれば、今後勉強していく中でも迷うことが少ないはずです。
実際に手を動かしてみたい方は、Python+PyTorch+MNIST(手書き数字認識)からはじめるのがおすすめです。関連記事も順次公開していく予定ですので、お楽しみに!

コメント