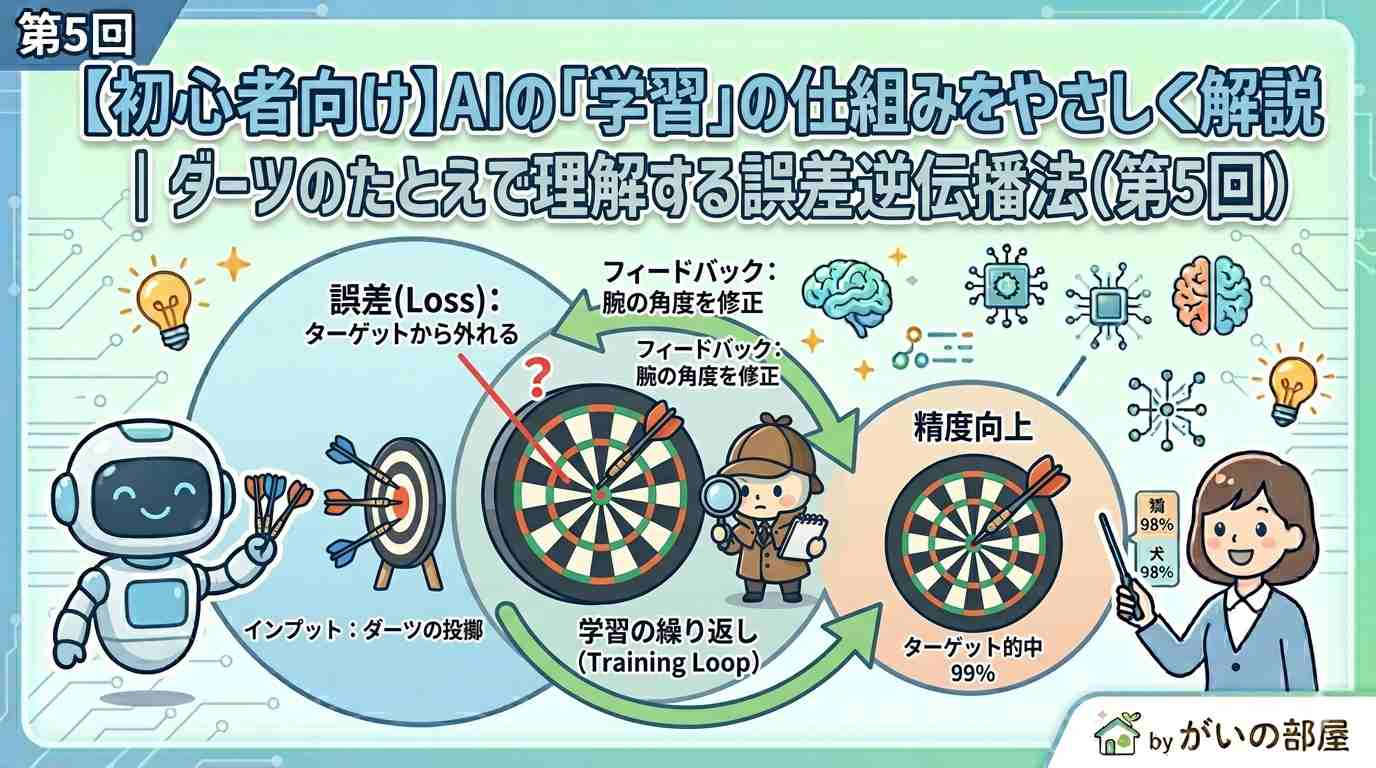
前回はフィルタの中身が「数字の表」だとお話ししました。では、その何百万個もある数字をどうやって賢く調整しているのか? 今回は AIの学習の仕組み を、ダーツの練習や霧の中の山下りのたとえで一気に理解しましょう。
1. 学習の全体像をひとことで
「予想する → 答え合わせする → 間違いを修正する」を何百万回も繰り返すだけです。
子どもが自転車に乗る練習にそっくりです。乗ってみる→転ぶ→「次はもう少し右に体重を」と調整→また乗る…AIの学習もまったく同じ流れです。
2. ダーツの達人を目指そう(たとえ話)
ダーツ初心者のあなたが、真ん中に当てる練習をしているとします。
- 1投目:右上に20cm外れた → 次は少し左下に
- 2投目:少し近づいた → さらに微調整
- …100投目:ほぼ命中!
ポイントは「どっちに、どれくらい外れたか」が分かれば、修正方向が決まること。これがAIの学習そのものです。
3. AIの学習に置き換えると
| ダーツ | AI |
|---|---|
| 投げる | 予測する |
| ダーツの的 | 正解(ラベル) |
| 外れた距離 | 損失(ロス) |
| 投げ方の調整 | 重み・フィルタの数字の調整 |
| 100回練習 | 学習エポック |
具体例:猫を判定するAI
入力画像(猫) ↓ AIが計算 ↓ 予測:[猫: 0.3, 犬: 0.6, 鳥: 0.1] ← 犬と間違えた! 正解:[猫: 1.0, 犬: 0.0, 鳥: 0.0] ↓ ズレ(損失)= 大きい ↓ フィルタの数字を少し調整 ↓ 次回は[猫: 0.35, 犬: 0.55, 鳥: 0.1] ← 少し改善!
4. 「数字の調整」を具体的に:坂道を下るイメージ
あなたが 山の上にいて、麓の村まで降りたいとします。でも 霧で何も見えません。どうしますか?
→ 足元の傾きを感じて、下りの方向に一歩進む。これを繰り返せば、いずれ村に着きます。これが学習アルゴリズムの正体です。
「損失の山」を下る
損失(高い=間違い大、低い=正解に近い)
\ \
\ / \ \
\/ \/
🤖 → 🤖 → 🤖 → 🎯
最初 学習中 完成
間違い大 正解!
目標は 損失が一番低い場所(=正解)にたどり着くこと。
5. 「勾配」=坂の傾き
勾配(こうばい)とは、損失の坂の傾きのことです。勾配を見れば「どっちに動かせば損失が下がるか」が分かるのがポイント。
フィルタの数字が今 0.5 のとき: 「0.5を 0.6に増やすと損失↑」 → 減らすべき 「0.5を 0.4に減らすと損失↓」 → こっちに動かす! → 数字を 0.4 に調整
これを 全部の数字(何百万個!)に対して同時に行います。
6. 誤差逆伝播法(バックプロパゲーション)
名前は怖いですが、やってることはシンプル。「最後の出力での間違いを、入り口に向かって順番に伝えていく」仕組みです。
クラスでテストの点数が悪かったとき、原因を逆向きにたどるのに似ています。
テスト結果が悪い(出力の間違い) ↑ 最後の章の理解が浅かった(最終層の責任) ↑ 中盤の章でつまずいてた(中間層の責任) ↑ 最初の基礎が抜けてた(最初の層の責任)
AIでも同じように、最後の損失を後ろから前に伝えて、各層の責任(=勾配)を計算します。これを1回の学習で全層一気にやるのが誤差逆伝播法です。
7. 学習の流れ(全体像)
ステップ1: 画像を入力 ↓ ステップ2: 順方向に計算(順伝播)→ 予測を出す ↓ ステップ3: 損失を計算(正解とのズレ) ↓ ステップ4: 逆向きに勾配を計算(誤差逆伝播) ↓ ステップ5: フィルタの数字を更新(勾配に沿って少しずつ) ↓ 次の画像で繰り返し(何百万回!)
8. 学習率:一歩の大きさ
霧の中で坂を下るとき、一歩の大きさが重要です。これを 学習率(learning rate)と呼びます。
- 大きすぎる:通り過ぎてジグザグ、暴走の危険
- 小さすぎる:いつまでも着かない
- ちょうどいい:実務では
0.001あたりから始めることが多い
9. 実際の数字の調整例
学習1回目
今の数字 : w = 0.500
勾配(傾き) : +2.0 ← プラス=減らすべき
学習率 : 0.01
更新式: 新しいw = 0.500 - 0.01 × 2.0 = 0.480
学習2回目
今の数字 : w = 0.480
勾配 : +1.5
新しいw = 0.480 - 0.01 × 1.5 = 0.465
…続けると…
0.500 → 0.480 → 0.465 → 0.453 → … → 0.412
↑ 最適な値に収束!
たったこれだけのシンプルな計算を、すべての数字(何百万個)に同時にやっているだけです。
まとめ
| 用語 | やさしい意味 |
|---|---|
| 学習 | 予想→答え合わせ→修正の繰り返し |
| 損失 | 答えとのズレ(=間違いの大きさ) |
| 勾配 | 数字を動かす方向と強さ(坂の傾き) |
| 誤差逆伝播法 | 間違いを後ろから前に伝えて責任分担 |
| 学習率 | 一歩の大きさ(慎重 or 大胆) |
| エポック | 全データを1周学習すること |
AIの学習は「魔法」ではなく、「ちょっとずつ間違いを減らす作業」を超高速で繰り返しているだけ。人間が自転車やダーツを練習するのと、本質的には同じです。
ところで、学習しすぎると逆にダメになる「過学習」という現象があります。次回はこの不思議な現象を解説します!
コメント